> ## Documentation Index
> Fetch the complete documentation index at: https://docs.kubox.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Audio Analysis with Machine Learning
> Transcribe, extract entities and summarise audio files.
## Introduction
In today’s information world, audio is one of the richest, yet most under utilised sources of data. Think about customer service calls, court hearings, public health and safety hotlines, signal intelligence, these conversations hold critical insights that are often trapped in raw recordings that are unsearchable and unstructured.
## Solution
This example demonstrates an end-to-end ML pipeline that transcribes audio, extracts entities, and summarises content using self-hosted models. It uses [Open AI Whisper](https://github.com/openai/whisper) for transcription and [Llama-3.2](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/) for summarisation on Kubox, optimised for NVIDIA L4 GPUs on AWS. The system processes an hour-long audio in just 20 seconds at a cost of around 10 cents.
 ## ML Pipeline
For efficient distributed processing, we deploy our ML pipeline using [Ray](https://www.ray.io) on Kubox, enabling self-hosted distributed transcription and summarisation with GPU acceleration. The pipeline consists of three key stages:
1. For transcription, we use [Open AI Whisper](https://github.com/openai/whisper), a state-of-the-art speech recognition model to convert audio to text. The large (1.5GB) model runs on Ray Workers within Kubox, leveraging NVIDIA L4 GPUs for fast, high-accuracy transcription of audio.
2. Once transcribed, [spaCy’s en\_core\_web\_sm](https://spacy.io/models/en) extracts named entities such as people, organisations, locations and legal references. This categorises unstructured text, improving searchability and filtering.
## ML Pipeline
For efficient distributed processing, we deploy our ML pipeline using [Ray](https://www.ray.io) on Kubox, enabling self-hosted distributed transcription and summarisation with GPU acceleration. The pipeline consists of three key stages:
1. For transcription, we use [Open AI Whisper](https://github.com/openai/whisper), a state-of-the-art speech recognition model to convert audio to text. The large (1.5GB) model runs on Ray Workers within Kubox, leveraging NVIDIA L4 GPUs for fast, high-accuracy transcription of audio.
2. Once transcribed, [spaCy’s en\_core\_web\_sm](https://spacy.io/models/en) extracts named entities such as people, organisations, locations and legal references. This categorises unstructured text, improving searchability and filtering.
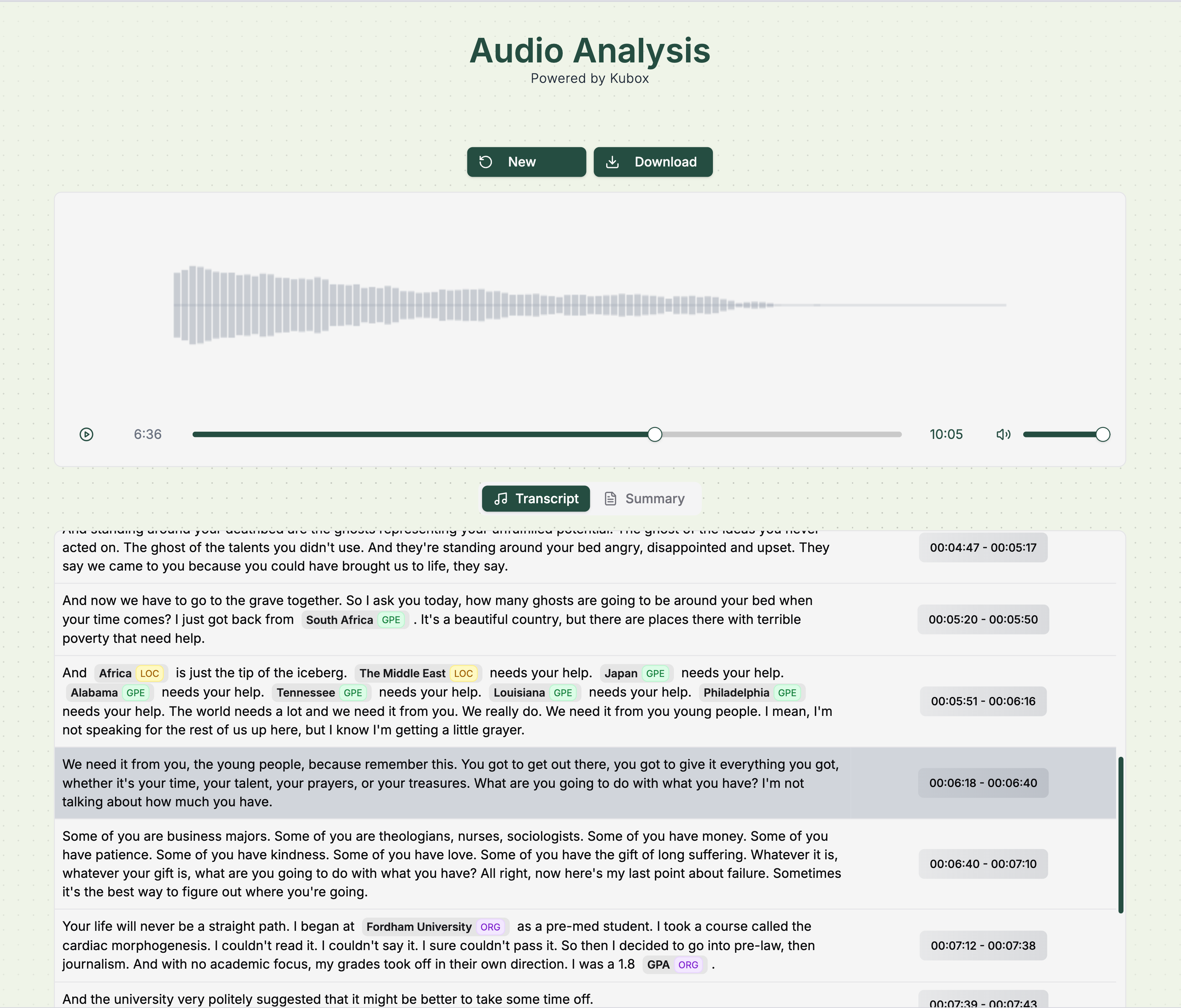 3. Finally for summarisation, a memory optimiseed [Llama-3.2-3B-Instruct-FP8](https://huggingface.co/neuralmagic/Llama-3.2-3B-Instruct-FP8) runs on Ray-powered GPU nodes, delivering concise, high-quality summaries. This self-hosted model ensures rapid processing, distilling an hour-long audio into key insights in just 20 seconds.
## SaaS vs Self-hosted
SaaS based audio analysis solutions offer scalability, minimal setup, and seamless access to continuously updated AI models. However, Kubox provides full control over sensitive data, automates infrastructure management and offers the flexibility to fine-tune or replace AI models without vendor lock-in. Below is a comparison of the approximate cost to process one hour of audio across various SaaS services.
| Service | Cost | Notes |
| :-------------------- | :--------- | :------------------------------------------------------------------------------- |
| Amazon Transcribe | **\$1.44** | \$0.024/min. Extra costs for custom vocabularies and call analytics. |
| Azure Speech-to-Text | **\$1.60** | \$1.60 per standard audio hour. Custom models cost extra. |
| Google Speech-to-Text | **\$1.44** | Cost is variable depending on the model. |
| OpenAI Whisper API | **\$0.36** | Lower cost, but cloud-hosted with no guaranteed data sovereignty. |
| **Kubox Audio-ML** | **\$0.10** | Based on self-hosting on AWS L4 GPUs. Full data control and customisable models. |
## Source Code
> Visit our Github repository at [https://github.com/kubox-ai/audio-ml](https://github.com/kubox-ai/audio-ml)
3. Finally for summarisation, a memory optimiseed [Llama-3.2-3B-Instruct-FP8](https://huggingface.co/neuralmagic/Llama-3.2-3B-Instruct-FP8) runs on Ray-powered GPU nodes, delivering concise, high-quality summaries. This self-hosted model ensures rapid processing, distilling an hour-long audio into key insights in just 20 seconds.
## SaaS vs Self-hosted
SaaS based audio analysis solutions offer scalability, minimal setup, and seamless access to continuously updated AI models. However, Kubox provides full control over sensitive data, automates infrastructure management and offers the flexibility to fine-tune or replace AI models without vendor lock-in. Below is a comparison of the approximate cost to process one hour of audio across various SaaS services.
| Service | Cost | Notes |
| :-------------------- | :--------- | :------------------------------------------------------------------------------- |
| Amazon Transcribe | **\$1.44** | \$0.024/min. Extra costs for custom vocabularies and call analytics. |
| Azure Speech-to-Text | **\$1.60** | \$1.60 per standard audio hour. Custom models cost extra. |
| Google Speech-to-Text | **\$1.44** | Cost is variable depending on the model. |
| OpenAI Whisper API | **\$0.36** | Lower cost, but cloud-hosted with no guaranteed data sovereignty. |
| **Kubox Audio-ML** | **\$0.10** | Based on self-hosting on AWS L4 GPUs. Full data control and customisable models. |
## Source Code
> Visit our Github repository at [https://github.com/kubox-ai/audio-ml](https://github.com/kubox-ai/audio-ml)